One of the greatest feelings as a developer, in my experience at least, is coming into a new project, hitting build, and then the whole project compiles with no issues. This is achieved with effective source control and proper project setup. For the purposes of this discussion I will talk about my experiences achieving this sort of bliss using Git and Qt. Git and Qt are the main tools I use day to day in my development workflow. Git is a common source control program. Qt is a cross platform C++ framework.
If you are starting a new project, it might be more difficult to want to put in the effort to properly setup your project and source control because it might seem the benefit is not to you directly. It seems on the surface the main benefit is for the person that comes after you. This is a common trope among developers. A lot of the work you put in seems to be for the benefit for the person after you, for example writing clean code or writing comments. You may be able to follow your own code with no issue, but the next person may have no idea what you are doing. If your codebase has logical flow and uses traditional patterns and has comments where appropriate, your successor will spend less time getting up to speed and they will greatly appreciate your efforts.
If this reason is not convincing enough for you, no worries, there are some self-serving benefits too, you narcissist. If you ever must move to a new development machine for example, you can pull the repo and build, and you are exactly back to where you were on your old machine. Maybe you are going back to an old project that you wrote and you don’t remember some of the intricacies of the logic or program flow, well you wrote good comments and uses regular patterns so you can spin back up on it in no time.
Project Setup
Effective project setup means all the external references are first included in the repo and secondly that they are reference in a generic way. If you use any absolute references, i.e. you use the full path to a library for example, then that reference will only be valid on your machine. In Qt for example, you reference things in relation to the project file, so if the library you want to use is two levels up and down a couple levels in another folder the reference might look something like, ../../libs/some_lib/lib.dll. The wrong way to do this, the absolute path, might look like, C:/Users/Me/my_repo/libs/some_lib/lib.dll.
Next, consider the project dependencies. If there are extra steps required after you build a project to run the application, try automating that either in the project file, if you can, or with a script of some sort. A good example of this is dll’s that your project might use. For your application to run, the executable might need to be in the same working directory as the dll’s that is uses. Maybe the first time you built the project you just moved those dll’s into the directory that the exe was built to. A better approach might be to have the project file move those dll’s directly. The approach that I find myself using quite often is settings a ‘deployment’ directory that has all the required dll’s, and then I just move the compiled exe into that directory. Either way you do this, remember that you want it to work the first time you build and hit run on a new machine.
One area where this might get maybe a bit more complicated than it’s worth is with system drivers. If it is required that I have the MSVC 2013 redistributable installed for my application to run because it uses some dependency that depends on that, then how do I make sure that that dependency is installed the first time? This type of thing is normally handled by the application installer which is a completely different topic. I would recommend just providing documentation for this in a README or something similar.
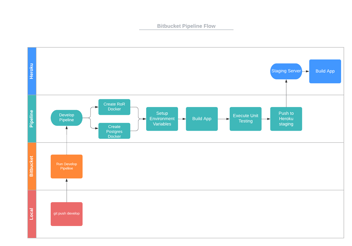
Git
.gitignore
A proper gitignore is important. First and foremost, we should try to not commit any compiled file. Well I should be more specific. You should not commit the compiled output of the project you are building. I think if you include dependencies like dll’s that is preferred because those are not a compiled product of your project and that is required for your project to run. A gitignore file also allows you to have a clean working copy. By default, git will try to track every file in the directory when really you only want it to track the source file for example. You don’t want it to track the .exe that you build or all the object files. Typically, all these products are put in a build folder of some sort so you can just add that folder to you gitignore file and they will be ignored. Now you do need to commit your gitignore file though. That way everybody else who pulls the project will also have those files ignored on their local machines as well.
Branching
Git flow is good, if not a little verbose for smaller projects. At a minimum I would always merge develop into master for every release and tag the version number. If it is a single developer project you might not need feature branches, unless you are working on multiple features at once. Otherwise commit often and always push often.
For larger projects with more developers, try and avoid making branches that never end. If you have a different branch that represents some specific build for some purpose, then when you make a change on develop it becomes difficult to keep that branch up to date. And then you might start branching off that branch for new features. But then you want develop to have that feature too so you try and merge the branch off the specific build branch into develop but you don’t want the specific changes of the build to be merge into main develop. This quickly turns into a hard to manage mess. Consider using pre-processor macros, or something similar, to control what kind of build you want instead of creating branches for specific builds.

This is the kind of thing we really should try to avoid, never ending branches.
In general, it’s a good idea to keep develop as the one source of the latest code.