

The Queued Message Handler (QMH) or Queue Driven Message Handler (QDMH) is the most ubiquitous architecture in LabVIEW; so much so that the high-level concept finds itself in significantly more advanced architectures such as the Actor Framework. The QMH forces process serialization and is not very efficient when individual processes take extended human time to execute.
The most basic QMH is a while loop with a queue as an input that carries a command/data message with shared data in the form of a shift register.
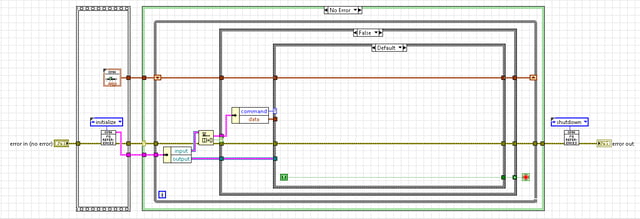
Limitations of QMH:
- Functions existing in a shared case structure forces all API to execute as if NRE via process serialization
- Functions that take significant time to complete will stall any other related functions
- High priority messages must wait on any currently running messages to finish
- QMH can be memory optimized by never optimized for execution
Process serialization (like data flow) is when one process must complete before another. When processes are serialized, the time to execute one process is equal to the sum of the time for each process to run. In the blog, How to Share Data and Mutexes in LabVIEW 1, the examples showed the difference in execution between re-entrant and non- re-entrant as well as the complication regarding sharing data. The QMH in a very basic way forces non re-entrant operation because each of the processes/functions are handled in a shared case structure.
The most efficient function/process is one where each instance of the command runs in its own loop with no connection to any other process or dependency; like how QMHs are modified so that certain processes run alongside the QMH will have their own while loop. Unfortunately, a fully independent process is generally NEVER a normal use case and as such there are three basic kinds of processes/functions:
- Independent - doesn’t affect or depend on any other processes during the normal use case.
- Dependent (external) - dependent on another process that is has not control over.
- Dependent (internal) - dependent on another process that is has no control over.
By organizing your modules with the above in mind, you can determine the degree to which a process can be parallelized. It will also allow you to grow beyond the QMH ideology by placing the’ functionality’ inside the API rather than the API being a means to access the functionality. By doing this, we have the flexibility to maximize the efficiency of certain processes.
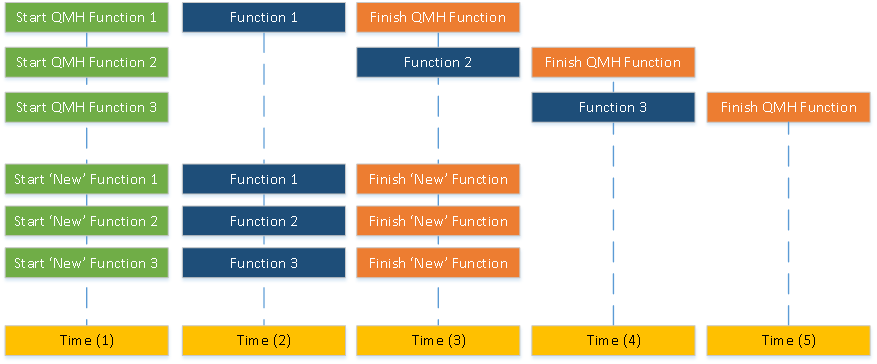
This ‘new’ architecture requires the following:
- Protected shared data storage that can be accessed in parallel
- Functions that can truly run in parallel
- Implementation that allows running in parallel
In the final part of the Sharing Data and Mutexes in LabVIEW blog series, we’ll introduce an implementation of this ‘new’ architecture as well as scalable solutions to the above requirements.


