Assumptions: Machine has a Nvidia CUDA Core GPU (such as a GeForce) with installed Nvidia Drivers.
Note: CUDA abstractions described below are included within the CUDA dev kit library and can only be compiled using NVCC. NVCC is the C++ CUDA toolkit compiler and produces binaries only for Nvidia Hardware. Other GPU Hardwares are not applicable. For AMD targets, refer to the AOCC compiler system or AMD µProf suite.
This is a simple introduction to NVCC and creating CUDA GPU targeted code. For more information about CUDA abstractions as well as other NVCC utilities, refer to the CUDA Toolkit Documentation.
In the previous chapter of this series, I had introduced how program execution could be allocated to a Nvidia Graphics Device using the CUDA dev kit library. In this iteration, I will give a more in-depth explanation of the CUDA thread hierarchy. Understanding the thread hierarchy will allow the programmer to maximize efficiency when architecting the execution distribution to a CUDA device.
Threads
A thread is a singular context of instruction execution and is the most basic unit of the CUDA thread hierarchy. In terms of purpose, a CUDA thread is no different than a traditional processor thread.
Thread Blocks
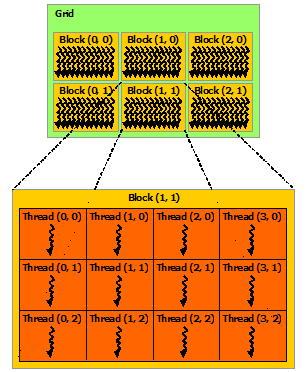
A group of threads is known as a thread block. The threads can be organized and indexed as 1 (x only), 2 (x and y) or 3 (x, y and z) dimensions within a block. As of the time that this post was authored, the maximum thread limitations for a block are: x-dimension <= 1024 threads, y-dimension <=1024 threads, z-dimension <=64 threads where x * y * z <= 1024 total threads.
Not only does each thread within a block have its own local memory space, but the thread block also has a shared memory space that is accessible to each thread within the block. Thread synchronization within a thread block should be exercised when utilizing the shared memory space to coordinate each thread’s access. With this functionality, threads within a block may execute either independently or dependently, based upon their use of the shared memory space.
Grids
A grid is a collection of thread blocks. Thread blocks can be organized as 1 or 2 dimensions within a grid. As of the time that this post was authored, a grid can have a maximum of 65535 thread blocks in each dimension.
Thread blocks within a grid execute independently of each other with the assumption that there will be no guaranteed order of their execution since that is determined at run-time. This is a contributor to NVCCs automatic scalability across hardware variances of different Nvidia CUDA devices. This will become more evident down below in the hierarchy to hardware translation.
Figure 4. Grid of Thread Blocks from the Nvidia CUDA Tool Kit Documentation showing the relation of Grids, Thread Blocks and Threads is below:
Hardware
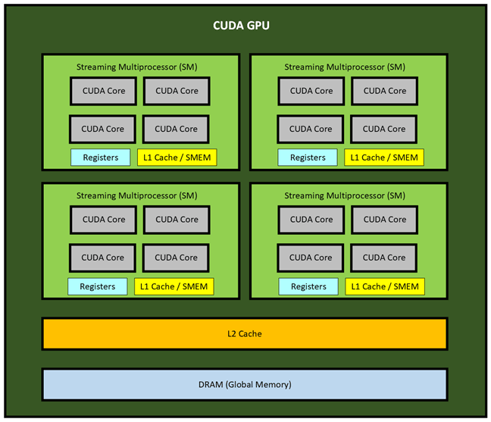
A Nvidia CUDA GPU is composed of several CUDA streaming multiprocessors (SM). An SM can be thought of as a processing unit which contains multiple cores, like how an ordinary desktop CPU will contain a specified number of cores. However, the cores that are contained within an SM are known as CUDA cores. Like a CPU core, CUDA cores can host multiple threads, but a CUDA core on its own will have less processing capability than a CPU core. Due to this difference, the SM will achieve its power through a much greater number of CUDA Cores. These SMs work in-parallel as a collective and are what determine the capabilities of the host GPU.
The amount of SMs a GPU has will depend on its architecture and model. For example, a GeForce 1080 Ti GPU has 28 SMs, each one containing 128 CUDA cores for a total of 3584 cores, while the new RTX 3080 Ti GPU has 80 SMs, each one with 128 CUDA cores for a total of 10280 cores. The GeForce 480 Ti from 2010 contained 16 SMs, each one with 32 cores for a total of 512 cores.
Below is a simple illustration of a CUDA GPU with 4 SMs, with each having 4 cores for a total of 16 CUDA Cores:
Hierarchy to Hardware Translation
If you remember from the last chapter of this series, we had called our revised matrixAddition() function to execute as a kernel on the GPU:

When invoking a kernel, it is required to specify the amount of thread blocks and the number of threads per block which will execute the kernel-specified routine. Above, we specified the kernel grid <<< # thread blocks, # threads / block >>> where:
amount of thread blocks = row_num = 3
amount of threads per block = col_num= 3
since we were adding two 3x3 matrices.
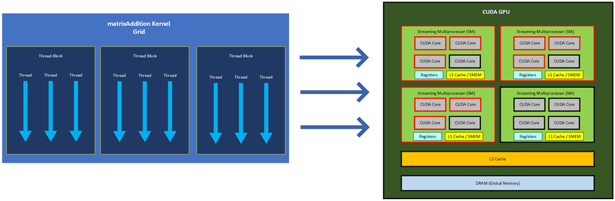
An invoked kernel will result in a grid of thread blocks to be assigned to the CUDA GPU. Each thread block within the kernel grid will be assigned an SM. Then each thread within the thread block will be assigned a CUDA Core of the SM that was assigned to the thread’s block.
This means that when we invoked the matrixAddition kernel from above, a grid of 3 thread blocks, each with 3 threads, was assigned to the GPU. Since each thread block gets its own SM, 3 SMs were active, and since there were 3 threads within each block, 3 cores within each of the 3 SMs were concurrently executing the routine specified in matrixAddition. Invoking cudaDeviceSynchronize() then allowed the program to wait for all cores within each SM to finish and synchronize before moving on to the last part of the code where we printed the result.
Below is a simple diagram which illustrates how the matrixAddition Kernel Grid executed the routine on the GPU, where the active SMs and CUDA Cores are outlined in red:
Multiple kernels can be run on a CUDA GPU at the same time. Each thread within the active CUDA core will then concurrently execute each kernel-specified routine assigned to it.
Conclusion
I hope this blog post has been helpful in providing a more in-depth explanation of the thread hierarchy as well as how a program will get distributed to a target CUDA device. Understanding the thread hierarchy is foundational in creating properly load-balanced applications that run efficiently on a CUDA GPU. In the next chapter of this series, I will go over the memory hierarchy.