Suposiciones: La máquina tiene una GPU Nvidia CUDA Core (como una GeForce) con controladores Nvidia instalados.
Nota: Las abstracciones CUDA descritas a continuación están incluidas en la biblioteca del kit de desarrollo CUDA y sólo pueden compilarse utilizando NVCC. NVCC es el compilador C++ del kit de herramientas CUDA y produce binarios sólo para Hardware Nvidia. Otros hardwares de GPU no son aplicables. Para objetivos AMD, consulte el sistema compilador AOCC o AMD µProf suite.
Esta es una simple introducción a NVCC y a la creación de código CUDA orientado a GPU. Para obtener más información sobre las abstracciones CUDA y otras utilidades de NVCC, consulta la documentación del kit de herramientas CUDA.
En el capítulo anterior de esta serie, había introducido cómo se podía asignar la ejecución de un programa a un dispositivo gráfico Nvidia utilizando la biblioteca del kit de desarrollo CUDA. En esta iteración, daré una explicación más profunda de la jerarquía de hilos CUDA. La comprensión de la jerarquía de hilos permitirá al programador maximizar la eficiencia en la arquitectura de la distribución de la ejecución a un dispositivo CUDA.
Hilos
Un hilo es un contexto singular de ejecución de instrucciones y es la unidad más básica de la jerarquía de hilos CUDA. En términos de propósito, un hilo CUDA no es diferente de un hilo de procesador tradicional.
Bloques de hilos
Un grupo de subprocesos se conoce como bloque de subprocesos. Los hilos pueden organizarse e indexarse como 1 (sólo x), 2 (x e y) o 3 (x, y y z) dimensiones dentro de un bloque. En el momento de redactar este post, las limitaciones máximas de hilos para un bloque son: dimensión x <= 1024 hilos, dimensión y <=1024 hilos, dimensión z <=64 hilos donde x * y * z <= 1024 hilos totales.
No sólo cada hilo dentro de un bloque tiene su propio espacio de memoria local, sino que el bloque de hilos también tiene un espacio de memoria compartida que es accesible a cada hilo dentro del bloque. La sincronización de hilos dentro de un bloque de hilos debe ejercerse cuando se utiliza el espacio de memoria compartida para coordinar el acceso de cada hilo. Con esta funcionalidad, los subprocesos de un bloque pueden ejecutarse de forma independiente o dependiente, en función del uso que hagan del espacio de memoria compartida.
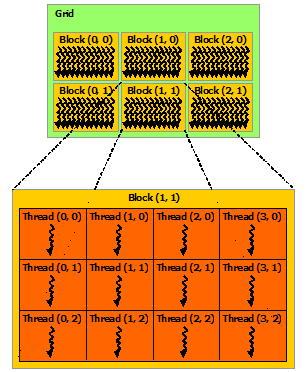
Rejillas
Una rejilla es una colección de bloques de hilos. Los bloques de hilos pueden organizarse en 1 o 2 dimensiones dentro de una rejilla. En el momento de escribir este post, una rejilla puede tener un máximo de 65535 bloques de hilos en cada dimensión.
Los bloques de hilos dentro de una rejilla se ejecutan independientemente unos de otros, asumiendo que no habrá un orden de ejecución garantizado, ya que éste se determina en tiempo de ejecución. Esto contribuye a la escalabilidad automática de NVCC a través de las variaciones de hardware de los diferentes dispositivos Nvidia CUDA. Esto se hará más evidente más adelante en la traducción de jerarquía a hardware.
Figura 4. A continuación se muestrala documentación de Nvidia CUDA Tool Kit que muestra la relación entre Grids, ThreadBlocks y Threads:
Hardware
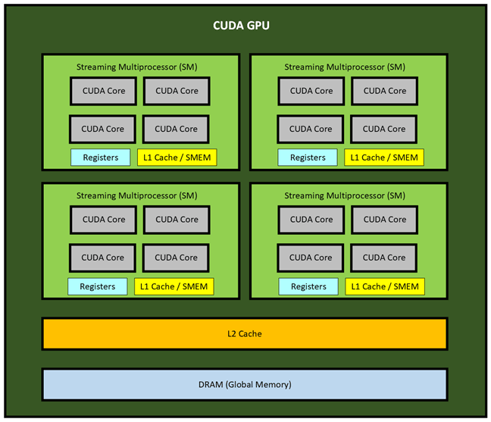
Una GPU Nvidia CUDA se compone de varios multiprocesadores CUDA (SM). Un SM puede considerarse como una unidad de procesamiento que contiene múltiples núcleos, al igual que una CPU de sobremesa normal contiene un número determinado de núcleos. Sin embargo, los núcleos que contiene un SM se conocen como núcleos CUDA. Al igual que un núcleo de CPU, los núcleos CUDA pueden alojar múltiples subprocesos, pero un núcleo CUDA por sí solo tendrá menos capacidad de procesamiento que un núcleo de CPU. Debido a esta diferencia, el SM alcanzará su potencia a través de un número mucho mayor de núcleos CUDA. Estos SM funcionan en paralelo como un colectivo y son los que determinan la capacidad de la GPU anfitriona.
La cantidad de SM que tenga una GPU dependerá de su arquitectura y modelo. Por ejemplo, una GPU GeForce 1080 Ti tiene 28 SM, cada una con 128 núcleos CUDA para un total de 3584 núcleos, mientras que la nueva GPU RTX 3080 Ti tiene 80 SM, cada una con 128 núcleos CUDA para un total de 10280 núcleos. La GeForce 480 Ti de 2010 contenía 16 SM, cada una con 32 núcleos para un total de 512 núcleos.
A continuación se muestra una ilustración sencilla de una GPU CUDA con 4 SM, cada uno con 4 núcleos para un total de 16 núcleos CUDA:
Traducción de jerarquía a hardware
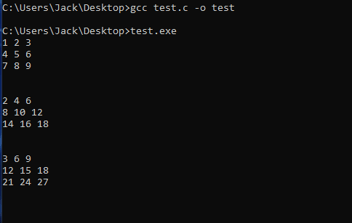
Si recuerdas el último capítulo de esta serie, habíamos llamado a nuestra función matrixAddition() revisada para que se ejecutara como un kernel en la GPU:

Al invocar un kernel, es necesario especificar la cantidad de bloques de hilos y el número de hilos por bloque que ejecutarán la rutina especificada por el kernel. Arriba, especificamos la rejilla del kernel <<< # bloques de hilos, # hilos / bloque >>> donde:
cantidad de bloques de hilos = row_num = 3
cantidad de hilos por bloque = col_num= 3
ya que estábamos sumando dos matrices de 3x3.
Un kernel invocado dará lugar a una rejilla de bloques de hilos que se asignarán a la GPU CUDA. A cada bloque de hilos dentro de la rejilla del kernel se le asignará un SM. Luego, a cada hilo dentro del bloque de hilos se le asignará un Núcleo CUDA del SM que fue asignado al bloque del hilo.
Esto significa que cuando invocamos el kernel matrixAddition de arriba, se asignó a la GPU una malla de 3 bloques de hilos, cada uno con 3 hilos. Como cada bloque de hilos tiene su propio SM, había 3 SM activos y, como había 3 hilos en cada bloque, 3 núcleos en cada uno de los 3 SM ejecutaban simultáneamente la rutina especificada en matrixAddition. La invocación a cudaDeviceSynchronize() permitió al programa esperar a que todos los núcleos de cada SM terminaran y se sincronizaran antes de pasar a la última parte del código, en la que imprimimos el resultado.
A continuación se muestra un sencillo diagrama que ilustra cómo el matrixAddition Kernel Grid ejecutó la rutina en la GPU, donde los SM y CUDA Cores activos aparecen delineados en rojo:
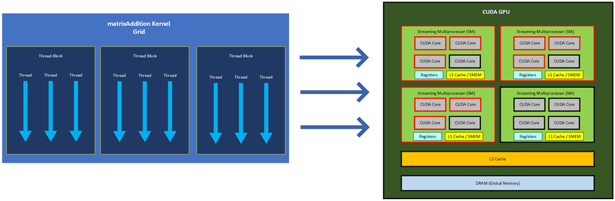
En una GPU CUDA pueden ejecutarse varios kernels al mismo tiempo. Cada subproceso dentro del núcleo CUDA activo ejecutará de forma concurrente cada rutina especificada por el kernel que se le haya asignado.
Conclusión
Espero que esta entrada del blog haya sido útil para proporcionar una explicación más profunda de la jerarquía de subprocesos, así como la forma en que un programa se distribuirá a un dispositivo CUDA de destino. Comprender la jerarquía de subprocesos es fundamental para crear aplicaciones con un equilibrio de carga adecuado que se ejecuten de forma eficiente en una GPU CUDA. En el próximo capítulo de esta serie, repasaré la jerarquía de memoria.