Assumptions: Machine has a Nvidia CUDA Core GPU (such as a GeForce) with installed Nvidia Drivers.
Note: CUDA abstractions described below are included within the CUDA dev kit library and can only be compiled using NVCC. NVCC is the C++ CUDA toolkit compiler and produces binaries only for Nvidia Hardware. Other GPU Hardwares are not applicable. For AMD targets, refer to the AOCC compiler system or AMD µProf suite.
This is a simple introduction to NVCC and creating CUDA GPU targeted code. For more information about CUDA abstractions as well as other NVCC utilities, refer to the CUDA Toolkit Documentation.
Heavy task loads can drastically take a toll on overall system performance, especially if they are only performed by the CPU. If a system has a GPU readily available, why not take advantage of this hardware? Utilizing the GPU alongside the CPU can increase the potential bandwidth of parallel and concurrent processing. The GPU is also more efficient than the CPU in certain applications, particularly operations commonly used in graphical rendering such as matrix transformation. In this post, I will show a simple example of how you can use a Nvidia GPU when developing an application.
Consider the following code which adds two 3x3 matrices using only the CPU:
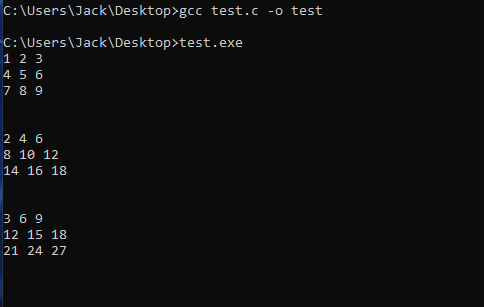
The C code from test.c can be compiled and run with the following commands:
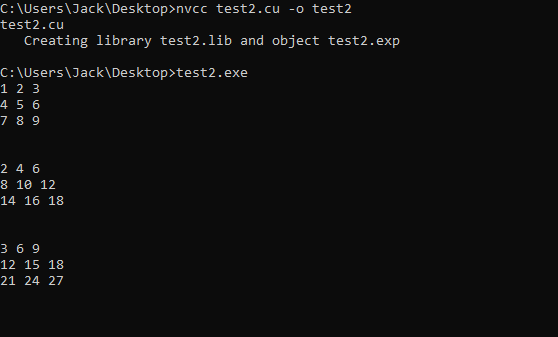
Offloading the above code to the GPU:
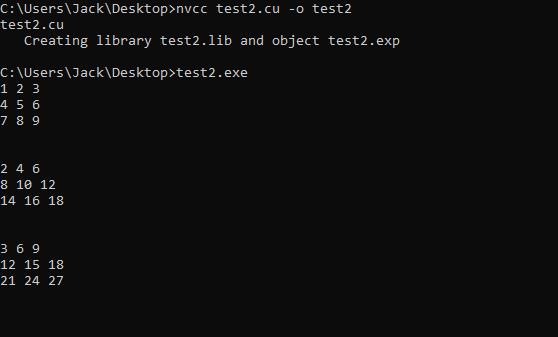
In order to offload to the GPU, we will need to invoke utilities which are available through the CUDA Toolkit development libraries in the following steps:
First, we need to provide a common address space between the host (CPU) and device (GPU). To do this, we use cudaMallocManaged to instantiate our pointers instead of malloc since malloc solely allocates memory on the host.
Next, we need to define our matrixAddition function with the __global__ keyword. This will indicate to the compiler that the matrixAddition function is called from the host but executed from the device.
Lastly, we need to adjust our matrixAddition function to be executed concurrently within the GPU device. To accomplish this, we will use a thread block (a collection of threads) for each row, and a thread within the thread block for each column across a row. To do this, we will convert matrixAddition to be a kernel – not to be confused with an Operating System kernel. A CUDA kernel is simply a function that is to be executed on the GPU device.
To create the matrixAddition kernel, we will specify <<<row_num, col_num>>> to the matrixAddition function call. The first parameter in the angled brackets, row_num, indicates that the kernel will execute within row_num amount of thread blocks, while the second parameter, col_num, indicates the number of threads within each thread block. Rather than using a for-loop within the MatrixAddition function to iterate across rows and columns during the calculation, we can use the thread block and thread ids as indexes into the matrices. The thread block and thread ids can be accessed with blockIdx.x and threadIdx.x, which are global CUDA device variables. Global CUDA device variables as well as other CUDA APIs are implicitly linked with our code when we compile with NVCC. We make sure to call cudaDeviceSynchonize() between the matrixAddition kernel call and the printing of the matrix which contains the calculation results to ensure that all threads of execution for the calculation have finished before attempting to print or use the result matrix.
The CUDA code from test2.cu can be compiled and run with the following commands:
Conclusion:
Now that we have learned how to utilize the GPU, an important question must be considered: Should we always offload to the GPU whenever possible? This greedy approach may initially sound like a good idea, however, there are some factors we should keep in mind when architecting how our program will execute on hardware. The CPU is a generic processing unit designed to execute just about any computation or instruction to a degree of efficiency. The GPU is a processing unit designed to execute a greater number of concurrent operations, usually ones used in video rendering, at a much greater efficiency. To accomplish these differences, the GPU is going to have much more processing cores, but at the cost of cache memory. Due to these traits, it would be best to designate the CPU for more generic, sequential tasks that would benefit most in caching or requiring many memory accesses, while using the GPU for computationally expensive tasks which can be executed concurrently with minimal interdependencies or memory caching requirements.
Supplemental Sources: