

In this final installment of this three-part series and a continuation of the separate but related blog 'The Queue[d Message Handler] is a Lie', the goal is to introduce a high-level methodology that can be used to develop an architecture for functionality that must operate asynchronously and can truly execute in parallel. Example code included!
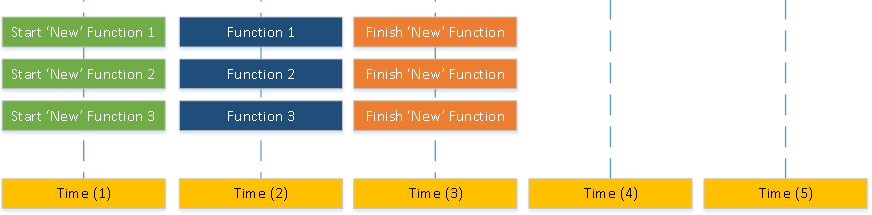
Recall, that the goal of this architecture is to reduce dependencies between function calls so they can run in parallel which can reduce the overall execution time for function calls. This methodology organizes functions into three types:
- Functions that need read/write access to shared data (Synchronous)
- Functions that need read-only access to shared data (Asynchronous)
- Functions that create references (Command)
Shared data is maintained in two locations:
- 1:1 blocking data structure such as a DVR or functional global
- 1:N non-blocking data structure such as a notifier, wires or global variable with a single/arbitrated writer
For functions that must modify shared data they first modify the blocking data structure, then update the 1:1 non-blocking data structure while functions that should only read data structures can read data using the non-blocking structure and perform its function.
Keeping in mind the situations outlined in ‘Protecting References in LabVIEW’, functions that create references must do so in VIs that don’t go idle. One solution is to create a ‘top level’ or ‘main’ VI that runs a mini queued message handler, but stays running so keep the reference from being cleaned up by LabVIEW.
Some challenges that may occur are:
- How to reduce calls to functional globals (to get references)
- How to create a non-re-entrant global for a module that is re-entrant
- How to handle situations where you may read old/bad data
- How to optimize for execution/memory usage
Calls to non-re-entrant functional globals can be reduced by storing the references in the calling function/api and only refreshing them on first call or if any of the references are no longer valid.
In situations where a read-only function may read bad/old data, it can be left to just output the error (e.g. a file handle is closed in a RW function but before the notifier is updated) OR functions can be written recursively where they can call themselves repeatedly until the issue is fixed or a certain number of calls have occurred.
Functions can be optimized for memory usage and execution by using shared clone re-entrant but this can make development/testing difficult (this is the only valid configuration if using recursive calls). Alternatively using pre-allocated shared clone will optimize for execution but not for memory usage BUT makes debugging significantly easier.
In the example code (found here), we have created four wait functions to simulate varying types of function calls:
- Wait - this function is totally independent/asynchronous and waits for the configured time
- Wait Mutex - this function is dependent on a mutex/semaphore and will not begin waiting until after it is able to acquire the semaphore
- Wait Shared - this function is independent but uses globally shared data
- Wait Error - this function works just like the ‘Wait’ function, but will randomly generate an error
The four examples benchmark multiple function calls using a QMH and the SocRep Architecture showing use cases where one may be faster than the other and vice-versa. In the fourth example, we run the same function multiple times within a for loop, one with parallel iterations and another with a conditional stop.
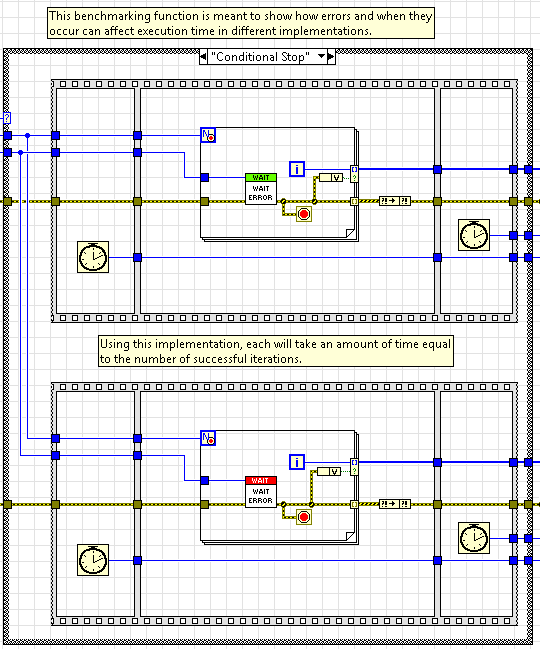
LabVIEW forces each iteration of the for loop to execute serially when the conditional stop is used so that it can check whether or not it should continue executing AFTER each completed iteration. This is a common use case when its safe to assume future iterations will also fail if any fail. In this situation, the benchmark between the two is approximately the same and there isn't a strong advantage to use the SocRep over the QMH.
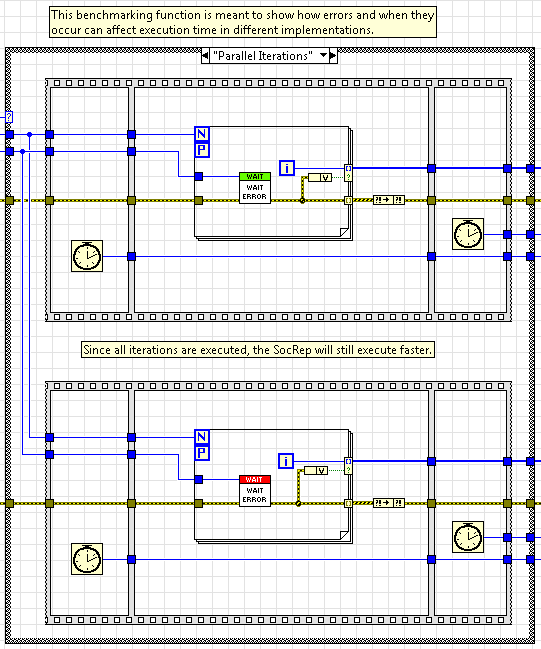
Alternatively, if we execute in parallel, we don't have access to the conditional stop, but we can selectively choose what data to output using the conditional input for the auto-indexing output terminal. Although we must let each iteration execute even if a previous iteartion fails, the SocRep's benchmark is significantly lower than the QMH's benchmark because the functions can truly execute in parallel.
Run each example and observe how the implementation of multiple calls affects the execution time.

