

En esta entrega final de esta serie de tres partes y continuación del blog separado pero relacionado'The Queue[d Message Handler] is a Lie', el objetivo es introducir una metodología de alto nivel que se puede utilizar para desarrollar una arquitectura para la funcionalidad que debe operar de forma asíncrona y que realmente puede ejecutarse en paralelo. Se incluye código de ejemplo.
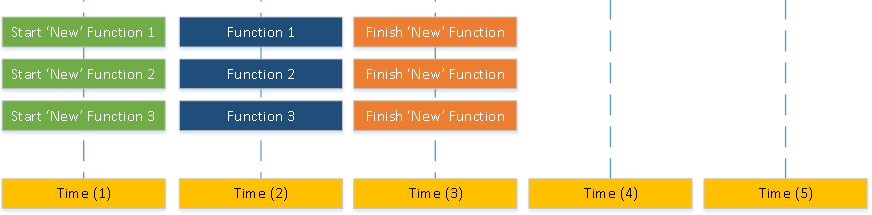
Recordemos que el objetivo de esta arquitectura es reducir las dependencias entre las llamadas a funciones para que puedan ejecutarse en paralelo, lo que puede reducir el tiempo total de ejecución de las llamadas a funciones. Esta metodología organiza las funciones en tres tipos:
- Funciones que necesitan acceso de lectura/escritura a datos compartidos (Sincrónicas)
- Funciones que necesitan acceso de sólo lectura a datos compartidos (Asíncronas)
- Funciones que crean referencias (Comando)
Los datos compartidos se mantienen en dos ubicaciones:
- 1:1 estructura de datos de bloqueo como un DVR o global funcional
- 1:N estructura de datos no bloqueante como un notificador, cables o variable global con un escritor único/arbitrado
Las funciones que deben modificar datos compartidos modifican primero la estructura de datos bloqueante y luego actualizan la estructura de datos no bloqueante 1:1, mientras que las funciones que sólo deben leer estructuras de datos pueden leer datos utilizando la estructura no bloqueante y realizar su función.
Teniendo en cuenta las situaciones descritas en 'Protección de referencias en LabVIEW', las funciones que crean referencias deben hacerlo en VIs que no estén inactivos. Una solución es crear un VI de 'nivel superior' o 'principal' que ejecute un mini manejador de mensajes en cola, pero que permanezca en ejecución para evitar que LabVIEW limpie la referencia.
Algunos retos que pueden surgir son:
- Cómo reducir las llamadas a globales funcionales (para obtener referencias)
- Cómo crear un global no reentrante para un módulo que es reentrante
- Cómo manejar situaciones en las que se pueden leer datos antiguos o erróneos
- Cómo optimizar la ejecución y el uso de memoria
Las llamadas a globales funcionales no reentrantes pueden reducirse almacenando las referencias en la función/api de llamada y refrescándolas sólo en la primera llamada o si alguna de las referencias ya no es válida.
En situaciones en las que una función de sólo lectura puede leer datos erróneos/antiguos, se puede dejar que sólo muestre el error (por ejemplo, un manejador de archivo se cierra en una función RW pero antes de que se actualice el notificador) O se pueden escribir funciones de forma recursiva en las que puedan llamarse a sí mismas repetidamente hasta que se solucione el problema o se haya producido un cierto número de llamadas.
Las funciones pueden ser optimizadas para el uso de memoria y ejecución usando clon compartido re-entrante pero esto puede dificultar el desarrollo/pruebas (esta es la única configuración válida si se usan llamadas recursivas). Alternativamente, el uso de clones compartidos pre-asignados optimizará la ejecución pero no el uso de memoria, PERO facilita significativamente la depuración.
En el código de ejemplo (que se encuentra enaquí), hemos creado cuatro funciones de espera para simular distintos tipos de llamadas a funciones:
- Wait - esta función es totalmente independiente/asíncrona y espera el tiempo configurado
- Wait Mutex - esta función depende de un mutex/semaphore y no comenzará a esperar hasta que sea capaz de adquirir el semáforo.
- Wait Shared - esta función es independiente pero utiliza datos compartidos globalmente
- Wait Error - esta función funciona igual que la función "Wait", pero generará un error aleatoriamente.
Los cuatro ejemplos comparan múltiples llamadas a funciones usando un QMH y la Arquitectura SocRep mostrando casos de uso donde uno puede ser más rápido que el otro y viceversa. En el cuarto ejemplo, ejecutamos la misma función múltiples veces dentro de un bucle for, una con iteraciones paralelas y otra con una parada condicional.
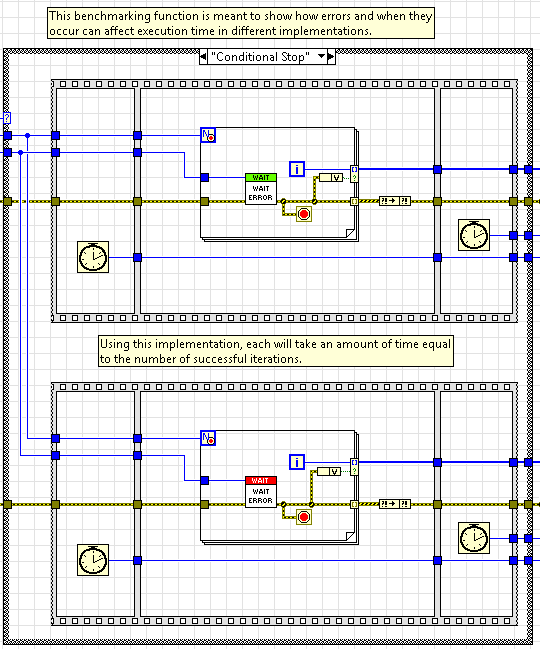
LabVIEW fuerza a cada iteración del bucle for a ejecutarse en serie cuando se utiliza la parada condicional, de forma que pueda comprobar si debe o no continuar ejecutándose DESPUÉS de cada iteración completada. Este es un caso de uso común cuando es seguro asumir que las iteraciones futuras también fallarán si alguna falla. En esta situación, el punto de referencia entre los dos es aproximadamente el mismo y no hay una gran ventaja para utilizar el SocRep sobre el QMH.
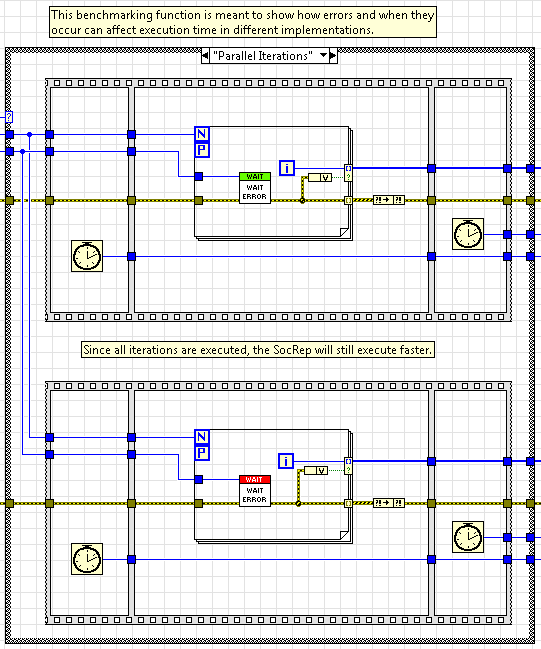
Alternativamente, si ejecutamos en paralelo, no tenemos acceso a la parada condicional, pero podemos elegir selectivamente los datos de salida utilizando la entrada condicional para el terminal de salida de auto-indexación. Aunque debemos dejar que cada iteración se ejecute incluso si una iteración anterior falla, el punto de referencia del SocRep es significativamente menor que el punto de referencia del QMH porque las funciones pueden realmente ejecutarse en paralelo.
Ejecute cada ejemplo y observe cómo la implementación de múltiples llamadas afecta al tiempo de ejecución.