

In LabVIEW, there’s a ton of stuff under the hood that can affect how you code runs and ultimately affect the functionality of your code. Have you ever debugged some code, turned on highlight execution and found that other pieces of code were also running slowly? Or have you found that sometimes a routine in your code runs slower when another [unrelated] process is running?
That could be because of blocking which is what mutexes do under certain circumstances. Mutex is short for a Mutual Exclusion object, its used for arbitration. It can be compared to a talking stick; often a mutex is used with shared resources to control who can access the shared data. In LabVIEW, mutexes are often implied. For example, a non re-entrant VI uses an implied mutex: only one instance of this kind of VI can execute at a time, thus when two instances attempt to execute simultaneously, only one can run and the other must wait until the other finishes: one instance blocks and the other instance has to wait.
Blocking is sometimes exactly what you want: a functional global encapsulates operations while modifying shared data which could cause race conditions if the functional global didn’t block. But there are also sometimes where blocking can hurt efficiency and your code will run slower when it doesn’t have to. Generally, the amount of time blocking occurs is negligible, except for situations where the code that’s blocking takes a significant amount of time to run.
Alternatively, a re-entrant VI will not block while other instances of it are running. Two instances of a re-entrant VI can execute simultaneously but, if there is a VI contained within (however deep) that is non-re-entrant that attempts to run simultaneously, it will block.
Traditionally, functional globals are always non re-entrant. This ensures that every instance of the functional global points to the exact same memory space. When not using non re-entrant execution, there is no easy way to ensure what memory location each instance of the VI is associated with therefore it’s difficult to ensure that you modify common data.
We’ve included three examples providing situations where mutexes are implied, how it can effect execution time and how execution modes affect functional globals. Source code is available here: lv_mutex_shared_1.zip
Example 01: Shows the difference between non re-entrant execution and re-entrant execution and how it affects execution time.
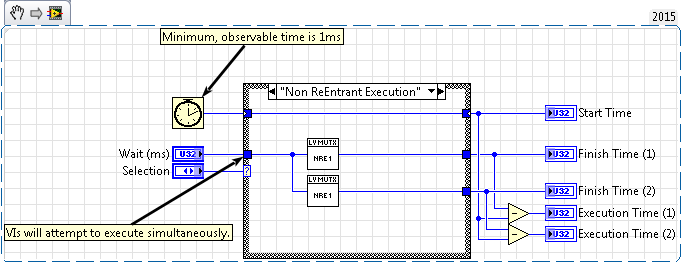
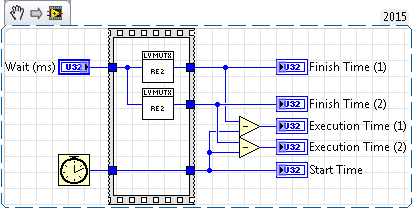
Example 02: Shows an example of two re-entrant VIs running simultaneously with a non re-entrant VI that attempts to run simultaneously in each re-entrant instance.
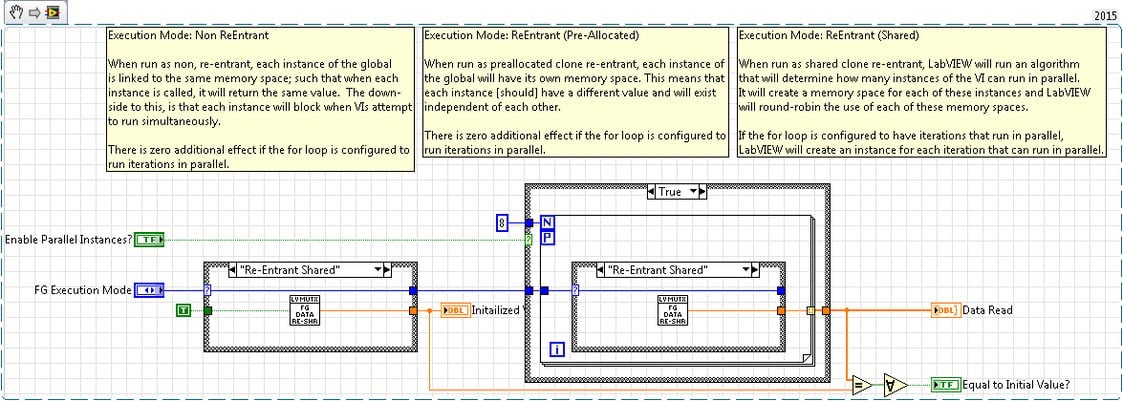
Example 03: Shows how different kinds of execution mode can affect functional globals and how it affects how each VI runs.
Some of this may push you to wonder how you can maintain speedy execution by reducing dependency on non re-entrant data sources using wires, but that also comes with its own problems. We provide a solution to this issue in the next installment of this blog series!
