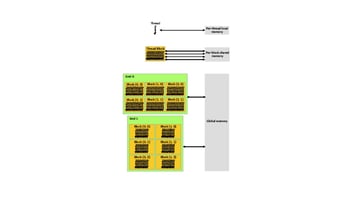
Supuestos: La máquina tiene una GPU Nvidia CUDA Core (como una GeForce) con los controladores Nvidia instalados.
Nota: Las abstracciones CUDA descritas a continuación están incluidas en la biblioteca del kit de desarrollo CUDA y sólo pueden compilarse utilizando NVCC. NVCC es el compilador de C++ del kit de herramientas CUDA y sólo produce binarios para hardware Nvidia. Otros hardwares de GPU no son aplicables. Para objetivos AMD, consulte el sistema compilador AOCC o AMD µProf suite.
Esta es una simple introducción a NVCC y a la creación de código CUDA orientado a GPU. Para obtener más información sobre las abstracciones CUDA y otras utilidades de NVCC, consulta ladocumentación del kit de herramientas CUDA.
La carga de tareas pesadas puede afectar drásticamente al rendimiento general del sistema, especialmente si sólo las realiza la CPU. Si un sistema tiene una GPU disponible, ¿por qué no aprovechar este hardware? Utilizar la GPU junto con la CPU puede aumentar el ancho de banda potencial del procesamiento paralelo y concurrente. La GPU también es más eficiente que la CPU en determinadas aplicaciones, sobre todo en operaciones utilizadas habitualmente en el renderizado gráfico como la transformación de matrices. En este post, mostraré un sencillo ejemplo de cómo se puede utilizar una GPU Nvidia al desarrollar una aplicación.
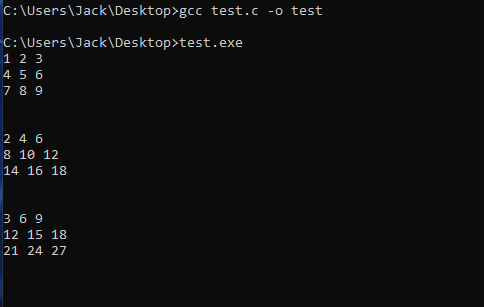
Consideremos el siguiente código, que suma dos matrices de 3x3 utilizando sólo la CPU:
El código C de test.c puede compilarse y ejecutarse con los siguientes comandos:
Descarga del código anterior en la GPU:
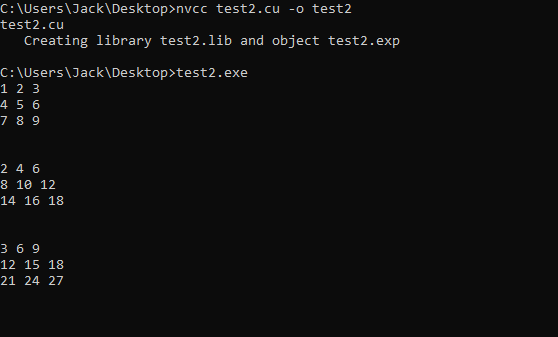
Para descargar a la GPU, necesitaremos invocar utilidades que están disponibles a través de las librerías de desarrollo del CUDA Toolkit en los siguientes pasos:
En primer lugar, tenemos que proporcionar un espacio de direcciones común entre el host (CPU) y el dispositivo (GPU). Para ello, utilizamos cudaMallocManaged para instanciar nuestros punteros en lugar de malloc, ya que malloc sólo asigna memoria en el host.
A continuación, tenemos que definir nuestra función matrixAddition con la palabra clave__global__. Esto indicará al compilador que la función matrixAddition se llama desde el host pero se ejecuta desde el dispositivo.
Por último, debemos ajustar nuestra función matrixAddition para que se ejecute de forma concurrente en el dispositivo de la GPU. Para ello, utilizaremos un bloque de subprocesos (una colección de subprocesos) para cada fila y un subproceso dentro del bloque de subprocesos para cada columna de una fila. Para ello, convertiremos matrixAddition en un kernel, que no debe confundirse con el kernel de un sistema operativo. Un kernel CUDA es simplemente una función que se ejecuta en la GPU .
Para crear el kernel de matrixAddition , especificaremos <<<row_num, col_num>>> a la llamada a la función matrixAddition. El primer parámetro entre corchetes, row_num, indica que el kernel se ejecutará dentro de la cantidad row_num de bloques de hilos , mientras que el segundo parámetro, col_num, indica el número de hilos dentro de cada bloque de hilos.En lugar de utilizar un bucle for dentro de la función MatrixAddition para iterar a través de filas y columnas durante el cálculo, podemos utilizar el bloque de hilos y los identificadores de hilos como índices en las matrices. Se puede acceder al bloque de hilos y a los identificadores de hilos con blockIdx.x y threadIdx.x, que son variables de dispositivo CUDA globales. Las variables de dispositivo CUDA globales, así como otras API de CUDA, se enlazan implícitamente con nuestro código cuando compilamos con NVCC.Nos aseguramos de llamar a cudaDeviceSynchonize() entre la llamada al kernel matrixAddition y la impresión de la matriz que contiene los resultados del cálculo para asegurarnos de que todos los hilos de ejecución del cálculo han finalizado antes de intentar imprimir o utilizar la matriz resultante.
El código CUDA de test2.cu puede compilarse y ejecutarse con los siguientes comandos:
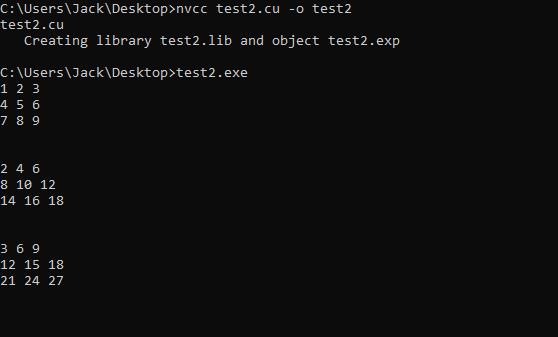
Conclusión:
Ahora que hemos aprendido a utilizar la GPU, debemos plantearnos una cuestión importante: ¿Deberíamos descargar siempre a la GPU siempre que sea posible? Este enfoque codicioso puede parecer inicialmente una buena idea, sin embargo, hay algunos factores que debemos tener en cuenta a la hora de diseñar cómo se ejecutará nuestro programa en el hardware. La CPU es una unidad de procesamiento genérica diseñada para ejecutar casi cualquier cálculo o instrucción con cierto grado de eficiencia. La GPU es una unidad de procesamiento diseñada para ejecutar un mayor número de operaciones simultáneas, normalmente las utilizadas en el renderizado de vídeo, con una eficiencia mucho mayor. Para lograr estas diferencias, la GPU va a tener muchos más núcleos de procesamiento, pero a costa de la memoria caché.Debido a estas características, lo mejor sería destinar la CPU a tareas más genéricas y secuenciales que se beneficien más de la memoria caché o requieran muchosaccesos a la memoria, mientras que utilizar la GPU para tareas de alto coste computacional que puedan ejecutarse de forma concurrente con mínimas interdependencias o requisitos de memoria caché.
Fuentes complementarias:
https://docs.nvidia.com/cuda/