Assumptions: Machine has a Nvidia CUDA Core GPU (such as a GeForce) with installed Nvidia Drivers.
Note: CUDA abstractions described below are included within the CUDA dev kit library and can only be compiled using NVCC. NVCC is the C++ CUDA toolkit compiler and produces binaries only for Nvidia Hardware. Other GPU Hardwares are not applicable. For AMD targets, refer to the AOCC compiler system or AMD µProf suite.
This is a simple introduction to NVCC and creating CUDA GPU targeted code. For more information about CUDA abstractions as well as other NVCC utilities, refer to the CUDA Toolkit Documentation.
IIn part 3 of this series, I will be introducing the NVCC CUDA Memory Hierarchy, and describing each component’s function during kernel execution on the GPU. The structure of the Memory hierarchy is the same and works similarly across all Compute Capability versions of Nvidia hardware, however, the specification of its implementation varies. Additional explanations can be found in sections 2.3 – Memory Hierarchy, 5.3.2 – Device Memory Accesses, or Section K for Compute Capability specifics in the CUDA Toolkit Documentation.
A sample of GeForce GPUs and their Compute Capabilities from https://developer.nvidia.com/cuda-gpus are listed below:
.png?width=648&name=MicrosoftTeams-image%20(10).png)
.png?width=556&name=MicrosoftTeams-image%20(18).png)
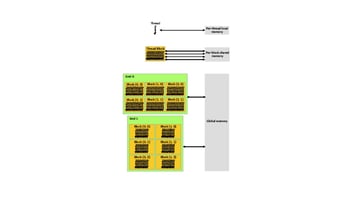
Figure 1 Memory Hierarchy Illustration from Section 2.3 in CUDA Toolkit Documentation
Local Memory
Each thread that is executing on the GPU device will be allocated its own segment of local memory. The localized memory segment will share a lifespan with its corresponding thread. Each segment of local memory can only be read-from or written-to by its corresponding thread and isn’t accessible outside of that thread’s context.
Designations to local memory are determined by the compiler and aren’t made by the programmer. The compiler will only place automatic variables into local memory, but not all automatic variables will exist in local memory. An automatic variable is a variable which is declared without a memory-space specifier. Memory-space specifiers and their purposes will be explained later in this blog.
Automatic variables that the compiler is most likely to allocate to local memory are: Arrays which are not found to be accessed in a consistent quantity, any structure which is too large to be stored in register memory, or if the executing kernel uses more registers than available.
Shared Memory
Shared memory is a segment of memory allocated to a block of threads and shares a lifespan with its thread block. Each thread within the block has read and write access to the block’s shared memory space. A block’s shared memory region is not accessible to threads outside of its corresponding block. Shared memory has a larger bandwidth than global or local memory, and accesses to it can be performed much faster. Due to how higher performance is achieved with banking, it is important that accesses made to shared memory adhere to specifications of the target’s Compute Capability. If ignored, latency speed may be penalized due to bank conflicts between requests. Compute Capability specifications are described in Section K of the CUDA Toolkit Documentation.
Global Memory
Global Memory within the GPU device is read and write accessible to every thread across all executing grids and thread blocks within. The Global Memory’s lifespan lasts the entirety of the CUDA context in which it was created. This memory can only be accessed 32, 64 or 128 bytes at a time. Read or write accesses to global memory must also be aligned to their size where the targeted address is a multiple of the transaction amount. To maximize global memory throughput, it is recommended that accesses are consistent with the global memory specifications of the target’s Compute capability.
Memory Space Specifiers
- __device__ - The declared variable will be stored in device (GPU) memory. This can be combined with other specifiers to further refine how a variable will be stored, but if this one is solely used, the variable will be stored in global memory.
- __constant__ - The declared variable will be stored in the Constant Memory.
- __shared__ - The declared variable will be stored in the Shared Memory.
- __grid_constant__ - The declared variable will be accessible and read-only to all threads within the same grid. This variable will also only be accessed with the same address across all threads of the grid. Only available in Compute-capability 7.0+ architectures.
- __managed__ - The declared variable can be referenced from both the host and device code and has a lifetime of the application.
- __restrict__ - Restricted pointer support. Ensures that pointers aren’t aliased to avoid register buffering and extra instruction execution.
Conclusion
Now that I have gone over thread and memory hierarchies in this blog series, the next entry will be the fun part of implementing design decisions based upon the thread and memory hierarchies into GPU-targeted code.