In the previous installment of this blog series we learned how the way in which we architect our applications can influence execution time: either allowing VIs to execute faster OR causing a VI to execute slower due to blocking. In this installment, we will cover methods to allow sharing data between parallel processes as well as their pros and cons. Example source code included!
In LabVIEW, data can be shared by reference or by value:
When data is shared by value, a copy of the data is made available to any sources that would like to use it. This copy is unique and in no way (other than the value it contains) linked to the source of the data. No blocking occurs when data is shared by value.
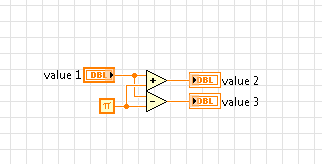
When data is shared by reference, any sources that want to access the data must access the same memory location to get the ‘value’ of the data. Some methods to access data by reference will block (such as Data Value References) by default, while others won’t block, but may not return the most current data (Notifiers).
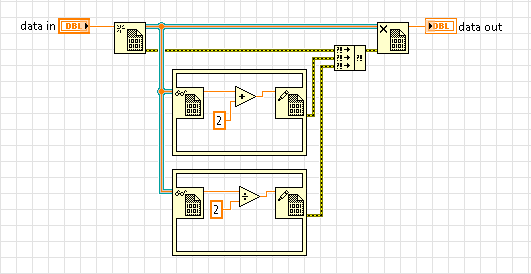
Sharing data via value provides the highest execution speed but as data is not stored in a common location, challenges can arise when data needs to be modified AND that modified data needs to be shared/updated.
Sharing data via reference provides the greatest architectural flexibility in that you are not limited by how your VIs are executing or their proximity to each other. Unfortunately, LabVIEW best practices would require some method of arbitration (e.g. functional global) which may block and reduce execution time noticeably.
I’ve included three examples of an implementation of a very simple Bank: one using local variables, one using shift registers and another using a functional global.

Using local variables to store the value of balance isn’t protected from read/write operations so there is a high possibility of a read/write/modify race condition. This can affect the function of the ‘bank’ where if a deposit and withdrawal are made simultaneously, the balance may not be correct.

Using shift registers to store the value of balance limits your architecture (e.g. performing a withdrawal outside the while loop), but eliminates the read/modify/write race condition in doing so. Any future additions that use or modify balance, must be contained within the while loop/event structure. In addition, this implementation of the bank cannot have truly simultaneous transactions.

Using a functional global to store the value of balance protects each individual operation so there is no possibility where a deposit and withdrawal happening simultaneously will create an incorrect balance.
The source code for the bank examples can be found here. In the final installment of this series, we will learn how to create a solution to get the best of both worlds and optimize our execution time while still being able to maintain our architectural flexibility by sharing data by reference.