

This is the first of a three-part series whose goal is to introduce what databases are and give some opinions about the available database technologies, why you should use them, and when you should use them in a non-technical way.

Often when a client wants to log data for a test, an ASCII file or an Excel spreadsheet are the go-to options, or even a TDMS (LabVIEW Specific) file when we need high speed streaming. However, sometimes, this is at the expense of the end user and to the ease of the developer. In some cases, storing information in a database can make the most sense and provide long-term advantages that otherwise wouldn’t be possible.
A database is a method of storage where information is organized into tables and tagged so that they can be accessed individually or en masse.
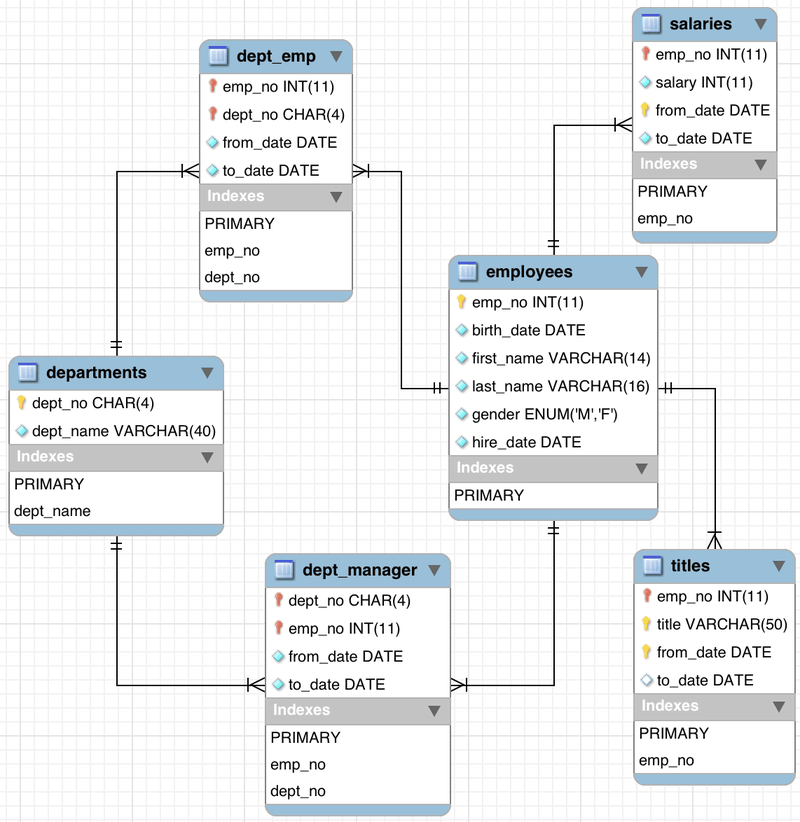
The database architecture for the sample employee’s database offered by MySQL
Often during the conception stage of a project, we try to understand what the finished product should look like as well as any future phases. If any of the following situations sound like something you may want or need in the future, a database may be a good choice to make on the front end of a project:
- Do you need to compare or put together statistics on data from multiple tests?
- Do you need non- real-time viewing of data?
- Do you need to access the data from tests in multiple places remotely?
- Are you worried that test data could be modified or deleted by accident?
- Do you need to synchronize common data?
- Do you need to sift through enormous amounts of data using known (or unknown) criteria?
Although we often approach development decisions from the perspective of using LabVIEW, the decision to use a database is relatively independent of the programming language.
In support of LabVIEW, a database can serve in a much more functional way to communicate data in a form that’s accessible by an enormous number of non-LabVIEW toolkits (e.g. Microsoft Access/Excel, PHP, Perl, ASP.net, etc.).
Below are some example situations in which using a database to store information shines.
EXAMPLE 1:

You run a company that performs quality control on products built in-house, and you store data from each of those quality control processes in a database.
Information is gathered, such as:
- Product Type
- Date
- Time
- Ambient Temperature
- Weight
- Personnel
- Test Duration
- Product Creation date
Over the course of a year, 25% of your customers tell you that your product failed after a couple of weeks. Although you could replace the item with little internal cost, a subset of those customers still had issues with the products, which you subsequently had to replace or else the customer went to a competitor.
Unfortunately, this indicates a problem during production that isn’t caught during quality control. In general, you know exactly which models failed and can compare them to the models that didn’t fail and try to draw conclusions.
For the sake of argument, let’s assume that the problem was this:
Creating the product when ambient temperature was very high (thanks, Houston) causes products to fail more often.
Although possible to resolve using spreadsheets and CSV files or with any decent data viewer, a database is made specifically for determining these kinds of relations. You could run several queries to search for other products where personnel/weight/date/time and creation are similar to the failed items and draw conclusions.
EXAMPLE 2:

Your factory employs several bearings to processes that run year-round. Although predictive maintenance is important, it makes the most financial sense to have a passive system in place to periodically log data and some alarms in the event amplitudes exceed certain limits.
For each of the bearings in question, you log temperature, velocity, and acceleration using an encoder. The data acquisition system itself reads these values at 1Hz, while a short waveform of 50 rotations is gathered once an hour for storage into a database.
A predictive maintenance (PdM) or reliability technician can pore over that data at regular intervals or when an alarm triggers to diagnose.
Given that data, failures can be predicted, allowing you to get the most out of a bearing by scheduling replacement at intervals specific to your factory or having some indication of when problems may occur. Storing the data in a database also makes remote diagnosis possible.
Databases can act as a Rosetta Stone when it comes to getting your data into a form usable by your business units.
Join us for Installment #2 of This Blog Series: What Database Should I Use?
Now that we’ve answered the question of why you should use a database, join us for the next installment of this blog series where we answer the question “What database should I use?”


