Suposiciones: La máquina tiene una GPU Nvidia CUDA Core (como una GeForce) con controladores Nvidia instalados.
Nota: Las abstracciones CUDA descritas a continuación están incluidas en la biblioteca del kit de desarrollo CUDA y sólo pueden compilarse utilizando NVCC. NVCC es el compilador C++ del kit de herramientas CUDA y produce binarios sólo para Hardware Nvidia. Otros hardwares de GPU no son aplicables. Para objetivos AMD, consulte el sistema compilador AOCC o AMD µProf suite.
Esta es una simple introducción a NVCC y a la creación de código CUDA orientado a GPU. Para obtener más información sobre las abstracciones CUDA y otras utilidades de NVCC, consulta la documentación del kit de herramientas CUDA.
En la parte 3 de esta serie, presentaré la jerarquía de memoria NVCC CUDA y describiré la función de cada componente durante la ejecución del kernel en la GPU. La estructura de la jerarquía de memoria es la misma y funciona de forma similar en todas las versiones Compute Capability del hardware de Nvidia; sin embargo, la especificación de su implementación varía. Encontrará explicaciones adicionales en las secciones 2.3 - Jerarquía de memoria, 5.3.2 - Accesos a la memoria del dispositivo, o en la Sección K para obtener información específica sobre Compute Capability en la documentación del kit de herramientas CUDA.
A continuación se incluye una muestra de GPU GeForce y sus capacidades de cálculo en https://developer.nvidia.com/cuda-gpus:
.png?width=648&name=MicrosoftTeams-image%20(10).png)
.png?width=556&name=MicrosoftTeams-image%20(18).png)
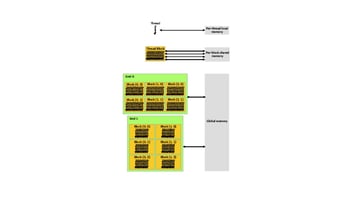
Figura 1 Ilustración de la jerarquía de memoria de la sección 2.3 de la documentación del kit de herramientas CUDA
Memoria local
A cada hebra que se ejecute en el dispositivo GPU se le asignará su propio segmento de memoria local. El segmento de memoria localizado compartirá una vida útil con su hebra correspondiente. Cada segmento de memoria local sólo puede ser leído o escrito por su subproceso correspondiente y no es accesible fuera del contexto de ese subproceso.
Las designaciones a la memoria local son determinadas por el compilador y no son hechas por el programador. El compilador sólo colocará variables automáticas en memoria local, pero no todas las variables automáticas existirán en memoria local. Una variable automática es una variable que se declara sin un especificador de espacio de memoria. Los especificadores de espacio de memoria y sus propósitos se explicarán más adelante en este blog.
Las variables automáticas que el compilador probablemente asignará a la memoria local son: Arrays que no se encuentran para ser accedidos en una cantidad consistente, cualquier estructura que sea demasiado grande para ser almacenada en memoria de registro, o si el kernel en ejecución utiliza más registros de los disponibles.
Memoria compartida
La memoria compartida es un segmento de memoria asignado a un bloque de hilos y comparte una vida útil con su bloque de hilos. Cada hilo dentro del bloque tiene acceso de lectura y escritura al espacio de memoria compartida del bloque. La región de memoria compartida de un bloque no es accesible a hilos fuera de su bloque correspondiente. La memoria compartida tiene un mayor ancho de banda que la memoria global o local, y los accesos a ella pueden realizarse mucho más rápido. Debido a cómo se consigue un mayor rendimiento con la banca, es importante que los accesos realizados a la memoria compartida se adhieran a las especificaciones de la Compute Capability del objetivo. Si se ignoran, la velocidad de latencia puede verse penalizada debido a conflictos de bancos entre peticiones. Las especificaciones de la Capacidad de Cálculo se describen en la Sección K de la Documentación del Kit de Herramientas CUDA.
Memoria global
La memoria global dentro del dispositivo de la GPU es de lectura y escritura accesible a todos los subprocesos a través de todas las rejillas en ejecución y los bloques de subprocesos dentro. La vida útil de la memoria global dura todo el contexto CUDA en el que se creó. A esta memoria sólo se puede acceder de 32, 64 o 128 bytes cada vez. Los accesos de lectura o escritura a la memoria global también deben estar alineados con su tamaño, donde la dirección de destino es un múltiplo de la cantidad de transacción. Para maximizar el rendimiento de la memoria global, se recomienda que los accesos sean coherentes con las especificaciones de memoria global de la capacidad Compute del objetivo.
Especificadores de espacio de memoria
- __device__ - La variable declarada se almacenará en la memoria del dispositivo (GPU). Esto puede combinarse con otros especificadores para refinar aún más cómo se almacenará una variable, pero si sólo se utiliza éste, la variable se almacenará en la memoria global.
- __constant__ - La variable declarada se almacenará en la memoria constante.
- __shared__ - La variable declarada se almacenará en la Memoria Compartida.
- __grid_constant__ - La variable declarada será accesible y de sólo lectura para todos los hilos dentro de la misma rejilla. Además, sólo se podrá acceder a esta variable con la misma dirección en todos los subprocesos de la red. Sólo disponible en arquitecturas Compute-capability 7.0+.
- __managed__ - La variable declarada puede ser referenciada tanto desde el código host como desde el código del dispositivo y tiene un tiempo de vida de la aplicación.
- __restrict__ - Soporte restringido de punteros. Garantiza que los punteros no tengan alias para evitar el almacenamiento en búfer de registros y la ejecución de instrucciones adicionales.
Conclusión
Ahora que he repasado las jerarquías de hilos y memoria en esta serie de blogs, la próxima entrada será la parte divertida de implementar las decisiones de diseño basadas en las jerarquías de hilos y memoria en el código orientado a la GPU.